P300 Speller
Designed a calibration-less single-trial classifier for P300 Speller
During the BCI and Neurotechnology Spring School 2021 organized by gtec, I had the opportunity to participate in the BR41N.IO hackathon, sponsored by IEEE Brain, along with some great people from all over the world.
We participated in the Data Analysis Projects category working with P300 Speller data to optimize preprocessing, feature extraction, and classification.
P300 Speller Data
Many advancements have been going on in the field of Brain-Computer Interface that now we can control any hardware device, be it a computer, wheelchair, or virtual environment, using our brain signals. One such important application of BCI is a spelling device to help people suffering from ALS communicate effectively. Many of such non-invasive spelling devices use P300 signals for detecting the letters the person wants to type.
P300 wave is an event-related potential, i.e. it gets elicited in the EEG signal when a person is introduced to some external stimulus, in this case, a flash of light. P300 waves can be identified as having a positive deflection in voltage around 250-500 ms after the stimulus is introduced. It is usually used in an oddball paradigm method, in which low-probability targets are mixed with high-probability targets.
In this project, subjects were asked to focus on the letter they wanted to type while each cell in a matrix of letters was getting flashed randomly. Whenever the letter, on which the subject is focusing, is flashed, it elicits the P300 signal which can be captured using the EEG device worn by the subject. Synchronizing this random flashing of letters and the elicited P300 signals will help to decode and present on screen the letter which the participant intended to type.
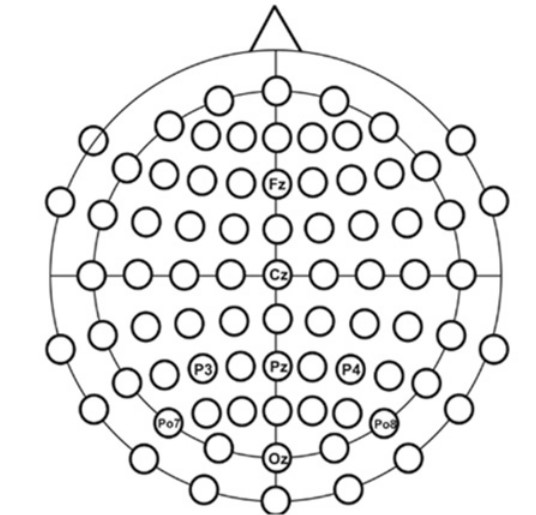
The data was recorded at a sampling frequency of 256 Hz using eight electrodes as illustrated below.
Data Preprocessing
First, the raw signals were band-pass filtered between 0.5 to 45 Hz, and the common average reference (CAR) spatial filter was applied for further processing. Next, the signal was separated into epochs of 0 - 1000 ms after the stimulus onset.
Data Augmentation
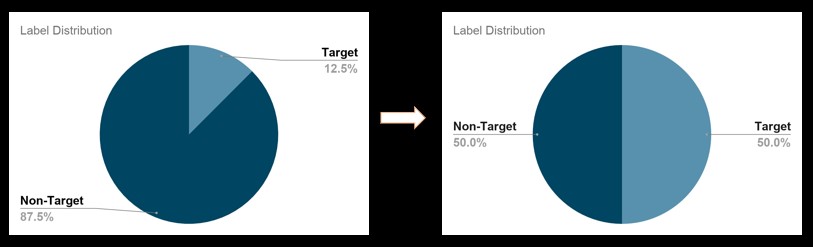
The data provided was collected from five subjects, which was less to train a classification model. Also, the uneven distribution of targets and non-targets creates several problems pertaining to imbalanced classification. We tried several methods of Data Augmentation to solve these two problems.
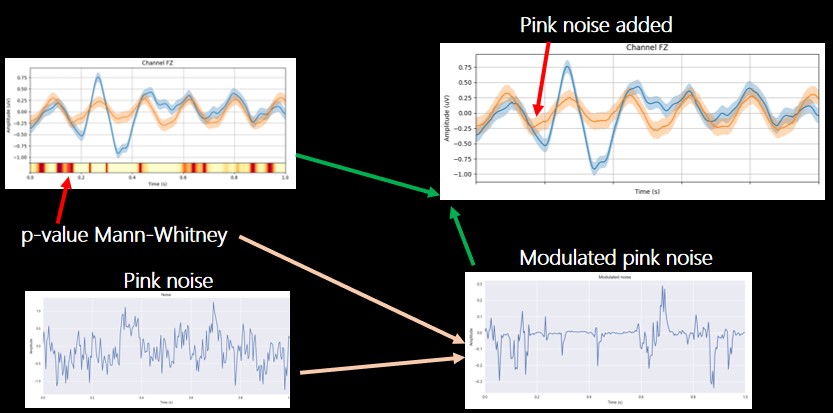
- Pink Noise Addition: The first approach for Data Augmentation was adding noise in the data. First, the less distinguishing areas in the signal were selected between targets and non-targets. The pink noise was modulated according to the data using the p-value Mann-Whitney Test and then it was added to the signal in the particular area.
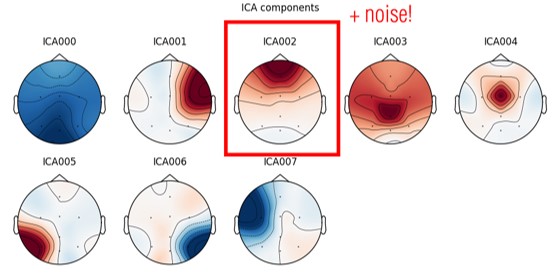
- ICA Components Decomposition: The second approach was to decompose the signal into eight Independent Component Analysis components. We chose the component related to frontal brain activity and added some noise to it. Lastly, we re-composed the signal to augment the original data.
- SVM SMOTE: The last approach we tried was SVM SMOTE (Synthetic Minority Over Sampling Technique). This was mainly done to balance targets and non-targets since targets and non-targets have a ratio of 1:7. In this method various synthetic points are created using k nearest neighbors method to balance the two classes.
Classification
For classification, we used a pre-trained deep convolutional neural network, with the following architecture.
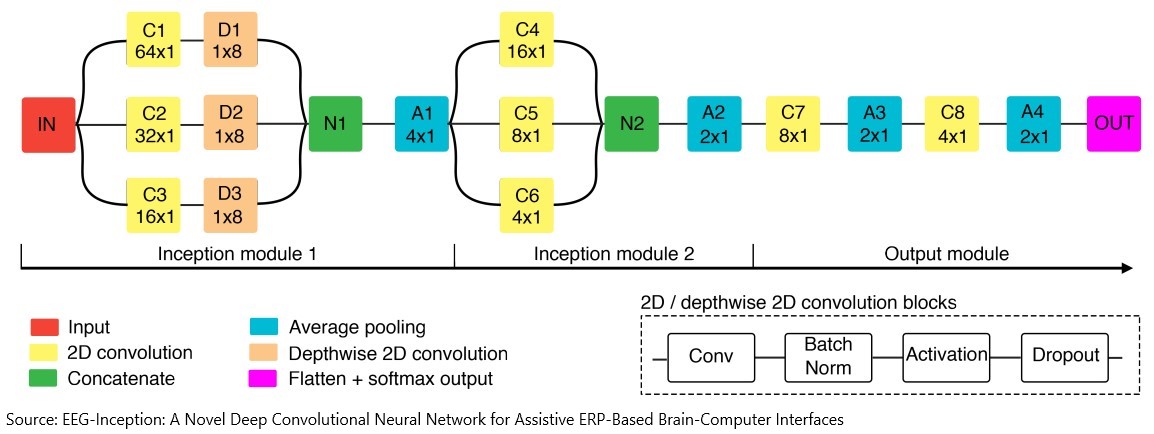
The inception modules in the architecture, originally used in computer vision, are adapted for EEG decoding. The network captures various feature dependencies in the dataset, just like we create feature maps in image classification tasks to visualize what each block in the network is learning. We used the Leave One Subject Out (LOSO) cross-validation for training the network. For fine-tuning the network, we used the above Data Augmentation techniques. The network achieved more than 90% accuracy for three of the subjects and more than 85% accuracy for the fourth subject in a single trial and data augmentation and fine-tuning improved the accuracy of classification.

The main aim of the project was to show that Deep Neural Nets can give a much better performance in calibration-less P300 paradigms. Transfer Learning and Data Augmentation are key features in our implementation and have proven effective measures to improve the accuracy of decoding.
Team : Eduardo Santamaría-Vázquez, Víctor Martínez-Cagigal, Sergio Pérez-Velasco, Diego Marcos-Martínez, Anjali Agarwal, Katherine Rojas
Watch the Hackathon Presentation
References
- E. Santamaría-Vázquez, V. Martínez-Cagigal, F. Vaquerizo-Villar and R. Hornero, “EEG-Inception: A Novel Deep Convolutional Neural Network for Assistive ERP-Based Brain-Computer Interfaces,” in IEEE Transactions on Neural Systems and Rehabilitation Engineering, vol. 28, no. 12, pp. 2773-2782, Dec. 2020, doi: 10.1109/TNSRE.2020.3048106.
- C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich, “Going deeper with convolutions,” Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, pp. 1–9, 2015