VOneNet: a Hybrid CNN
Analysis of VOneNet towards adversarial attacks.
Checkout the code here
Neuromatch Academy has reignited my curiosity and appetite for knowledge. I had the most fun learning and building projects in neuroscience and deep learning during the two-month-long interactive course.
During this time I got to collaborate with some awesome people and work on the analysis of CNN models that can prevent adversarial attacks on images.
VOneNet: a Hybrid CNN with a V1 Neural Network Front-End
With recent advances in Deep learning technology models can perform object detection tasks with high accuracy but are often fooled when adversarially attacked images are introduced. Images with some added noise or patch are called adversarially attacked images. These images can look the same to the human eye but can seem a completely different image to a highly accurate object detection model.

Designing CNN models that are robust to adversarial images is a challenge. However, recent research has suggested that the models that adopt/mimic the primary visual processing of primates are more likely to improve the robustness. The similarity in the CNN and primate visual cortex is a well-explored area of research. Though there are differences in the higher visual areas(V2, V3, V4, and so on), the primary visual cortex (V1) has been shown to have strong similarities in terms of its computation and representation.
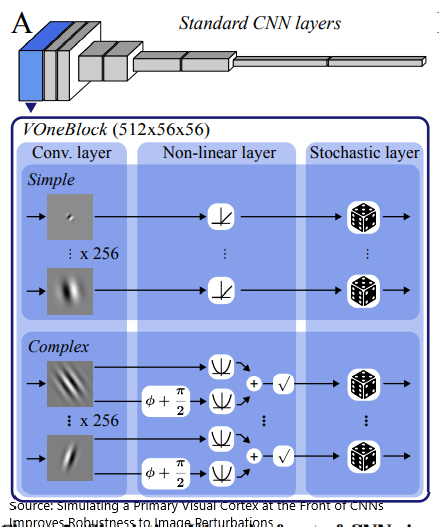
Leveraging this, VOneNets are used to combat the processing of image perturbations. VOneNet contains VOneBlock, which is a hybrid neural network with a fixed weight front-end, shares the linear, nonlinear, and stochastic properties of the first layer, that is meant to reflect primate V1 as input to standard CNNs.
Data
We used the Imagenet dataset for testing the pretrained models.
For adding adversarial attacks to the images we used the Foolbox library, implementing the DeepFool L-infinity attack.


Model Activations
ResNet50 model was used as the backend convolutional neural network. Therefore, for comparison, we used the vanilla ResNet50 model and the hybrid ResNet50 model with V1 network at the front end (VOneResNet50).
After testing the models with clean and perturbed images, we collected the activations from each layer to inspect and visualize the difference in activations of each model to clean and perturbed images.
Representational Dissimilarity Analysis
For analysis of activations, we used the Representational Dissimilarity Analysis (RDA) method (analogous to RSA). We used Pearson’s Correlation coefficient to find the similarity between the activations of the model for clean and perturbed images and converted it into a dissimilarity coefficient. In the figure below you can see the dissimilarity or deviation coefficients for the V1 Resnet model and the vanilla Resnet model for one of the ImageNet images.
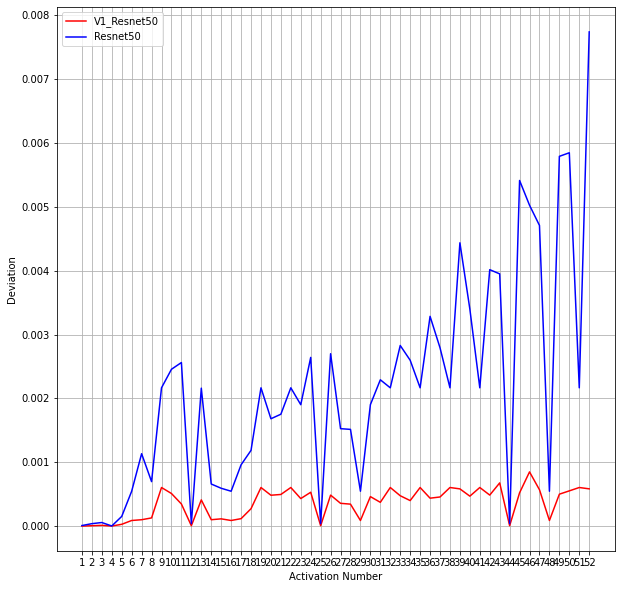
We can observe that the V1 Resnet50 model has a low deviation between the clean and perturbed image as compared to the vanilla Resnet50 model.
We can also note that at four points the deviation of both the V1 Resnet50 model and vanilla Resnet50 model is zero, i.e. there is no difference in the clean and perturbed image. This occurs at 4, 12, 25, and 44 points on the x-axis. This corresponds to layers:
4 - Layer 1, Bottleneck 0, Downsampling
12 - Layer 2, Bottleneck 0, Conv2
25 - Layer 3, Bottleneck 0, Conv2
44 - Layer 4, Bottleneck 0, Conv2
In fact, Conv2 blocks in every bottleneck of every layer are where we observe the dips. This observation can be generalized to all the images we tested the models on.
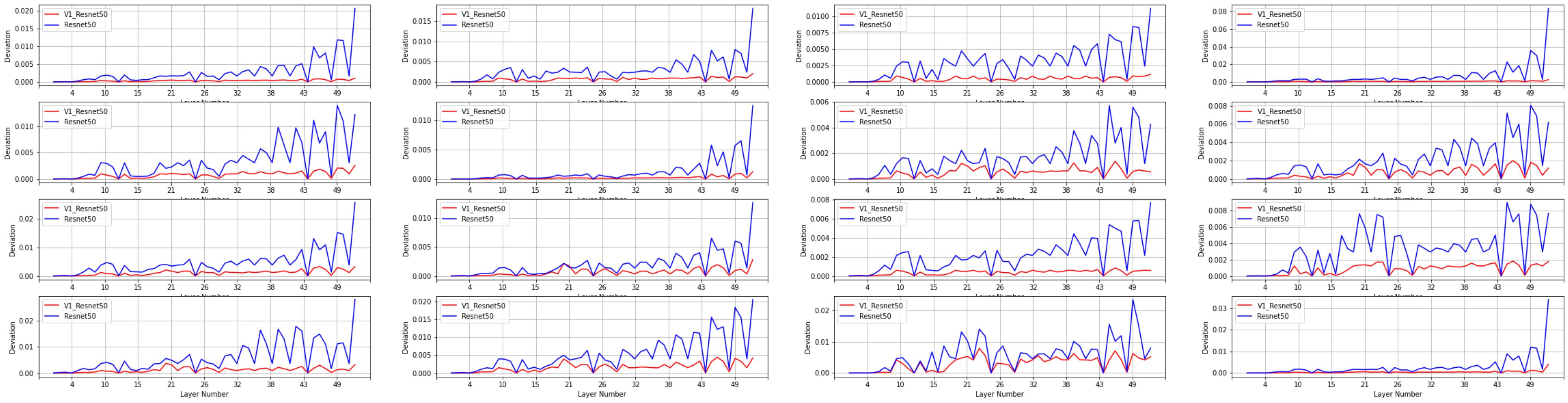
Image Visualization
For visualizing each activation as an image, we used PCA to lower the dimension of each activation and then reshaped it as an image.


Analyzing the images above, we can clearly see that although there is not much difference between V1 Resnet50 and Resnet50 model for clean images, for perturbed images there is a reasonable difference. This is because the V1 model is performing better on perturbed images than the Resnet50 model.
Conclusion
Here we inspected and visualized the activations we obtain when we run clean and perturbed images through a normal ResNet50 model and a hybrid ResNet50 model with the front end as the V1 block inspired from the V1 part of the human visual system. We observed that the deviation between activations for clean and perturbed images in the case of VOneNet is much lower than for the normal ResNet model which gives proof that the VOneNet model is robust and is not affected by adversarial attacks. Some more insights we built analyzing the deviation maps are the dips at specific layers where the deviation is zero for both the models, the occurrence of which is not clear and provides an opportunity for future work.
Team: Ishwarya Chandramouli, Anjali Agarwal, Ranjith Jaganathan
References
- Dapello, J., Marques, T., Schrimpf, M., Geiger, F., Cox, D.D., & DiCarlo, J.J. (2020). Simulating a Primary Visual Cortex at the Front of CNNs Improves Robustness to Image Perturbations. bioRxiv.
- Kriegeskorte, N., Mur, M., & Bandettini, P. (2008). Representational similarity analysis - connecting the branches of systems neuroscience. Frontiers in systems neuroscience, 2, 4. https://doi.org/10.3389/neuro.06.004.2008