Deception Detection
Developed an eye-tracking Deception Detection system.
Deception is a complex social behavior that involves a set of higher cognitive functions. Studying this common phenomenon in humans has in all epochs been driven not merely by the wish to understand the underlying framework of cognitive functioning but rather by the ambition to detect deceptive behavior in criminal suspects. Thus, identifying valid indicators of deceptive behavior has always been the focus of deception research. Various techniques have been proposed by researchers for the accurate detection of deception. In this report, one of such techniques has been used, called Eye Tracking data. This technique is more of a cognitive-based reaction. Lying or deceiving someone is a very stressful activity involving a lot of cognitive activity and can modify the eye behaviors which can be extracted and used for detection.
In addition to this, we also need to extract important features from the raw data like fixations, saccades, size of the pupil, blink rate. Eye Tracking is an important part of deception detection because unlike facial expressions and body language, eye movements are difficult to control consciously.
Experiment Paradigm
The guilty participants were instructed to attempt a mock theft and then lie about the crime while they answer a series of Yes/No questions. Innocent subjects were asked to answer the same questions, only they won’t be lying. The eyes of each participant were tracked while they answer the questions.
The setup of the experiment is as follows:
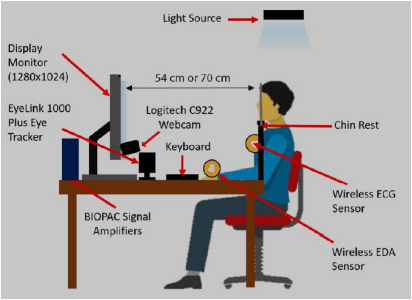
After receiving the raw eye-tracking data, they were processed using the python library created to extract various features from it, saccades, microsaccades, blink rate, pupil size, fixations.
Feature Engineering
Given that the above features extracted didn’t perform well during the classification, we tried to transform them using Feature Engineering. Feature Engineering, here, is based on the baselines that we created using the questions asked during the test. We have two important baselines, one for the truth and the other for the lie. We can use this to engineer new features which can prove helpful in the classification.
In this model, we will engineer new features using the features we already have. We will take the two baselines to find out the degree of truth and lie contained in the responses to the questions about the theft.
Feature Selection and Classification
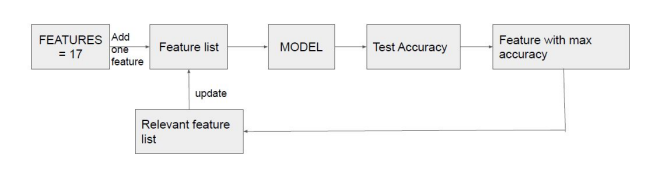
In all, we had 51 features for classification, and to find ones that would give the best classification score we used the Forward Selection method as described below:
The Machine Learning model used in this problem is Logistic Regression. Logistic Regression predicts the probability of occurrence of a binary event utilizing a logit function.
We divided the complete dataset into training and testing set in the ratio 7:3 so that both training and testing set has an equal proportion of the three subject categories. For robustness of the model, we implemented 100 trials of classification for the evaluation of every feature. In these 100 trials, each trial has a different set of subjects added to the training and testing set randomly chosen from the set of 62 subjects as explained above. After every set of 100 trials, a new feature that performed the best in the 100 trials is added to the relevant feature list. This process ends when we have all the features in the relevant feature list, arranged in the order of their importance in the model.
Results
The graph depicting the accuracy changing with the number of features added is shown below:
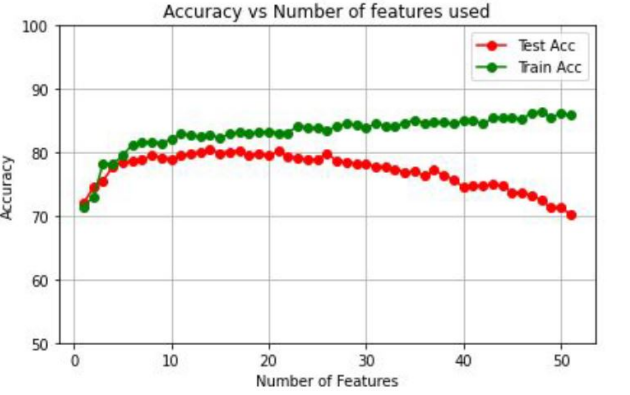
The maximum average accuracy obtained in this case is 80.5% for 14 features.
Next, we analyzed the outliers present in the data to improve the score more.
For finding the subjects that are being wrongly classified, the following steps are adopted:
- The features selected are taken from the above model. They are kept constant in the entire experiment.
- There are a total of 1000 trials done for each subject.
- In these 1000 trials, a specific subject is made to occur in every trial in the testing set. Using this, we can find the percentage of misclassification by calculating the number of times a subject has been incorrectly classified.
- The above step is performed for each of the 62 subjects. The subjects having a misclassification percentage greater than 50% are considered as outliers.
After removing the outliers we again trained and tested the model with the relevant feature list we found earlier. The result is as follows:
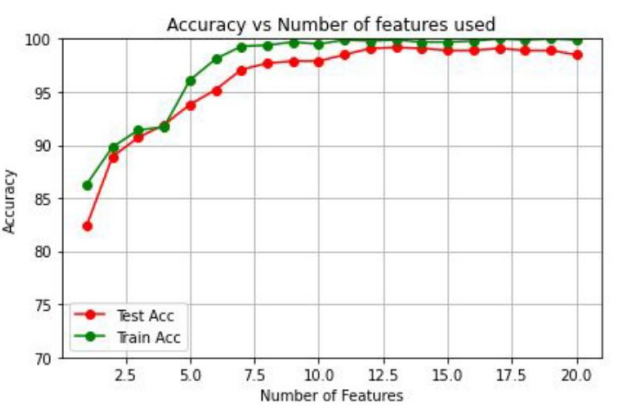
The maximum average accuracy obtained in this case is 99.2%.
References
- Cook, A. E., Hacker, D. J., Webb, A. K., Osher, D., Kristjansson, S. D., Woltz, D. J., & Kircher, J. C. (2012). Lyin’ eyes: ocular-motor measures of reading reveal deception. Journal of experimental psychology. Applied, 18(3), 301–313. https://doi.org/10.1037/a0028307
- Meijer EH, Verschuere B, Gamer M, Merckelbach H, Ben-Shakhar G. Deception detection with behavioral, autonomic, and neural measures: Conceptual and methodological considerations that warrant modesty. Psychophysiology. 2016;53(5):593-604. doi:10.1111/psyp.12609
- Kircher, John & Raskin, David. (2016). Laboratory and Field Research on the Ocularmotor Deception Test. European Polygraph. 10. 10.1515/ep-2016-0021.
- Vrij, Aldert & Fisher, Ronald & Mann, Samantha & Leal, Sharon. (2006). Detecting deception by manipulating cognitive load. Trends in cognitive sciences. 10. 141-2. 10.1016/j.tics.2006.02.003.
- Hacker, D. J., Kuhlman, B., & Kircher, J. C., Cook, A.E., and Woltz, D.J. (2014). Detecting Deception Using Ocular Metrics During Reading. In D. C. Raskin, C. R. Honts, & J. C. Kircher (Eds.), Credibility Assessment: Scientific Research and Applications. Elsevier, pp 159-216.
- K. K. Lim, M. Friedrich, J. Radun, and K. Jokinen, Lying through the eyes: detecting lies through eye movements,” GazeIn’13,, pp. 5156, 2013.